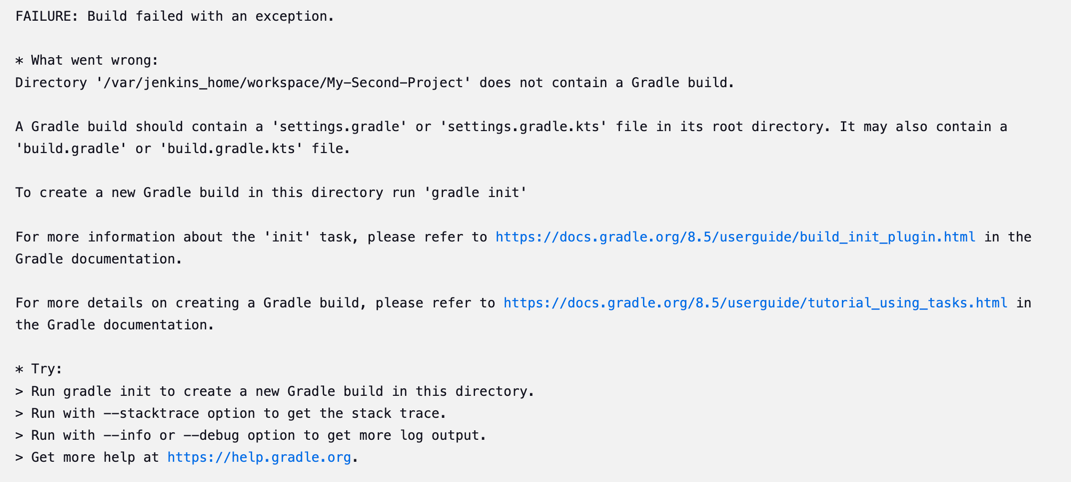
인프런에서 실습으로 배우는 선착순 이벤트 시스템이라는 재밌는 강의가 있어서 진행해 보았다. 커리큘럼을 보니까 Redis와 Kafka를 사용해서 진행하는데 Redis는 그렇다 치고, Kafka는 따로 사용해 본 적이 없어서 간단하게 경험하기 위해 진행했다.
최상용 강사님의 강의인데 이분 강의는 슬쩍슬쩍 알음알음 맛보기 좋은 강의인 것 같다. 재고 시스템을 구현하면서 동시성을 해결하는 강의도 이전에 들었는데 다시 들어보면서 정리해 볼 예정이다.
이 글에서 전체 코드를 보여주진 않으니 궁금한 사람은 해당 강의를 들어보는 것을 추천한다. 인프런이 할인을 자주해서 대충 20퍼 할인할 때 구매하면 정가인 느낌이다.(정가가 아까운 강의는 아니다.)
Docker와 MySQL
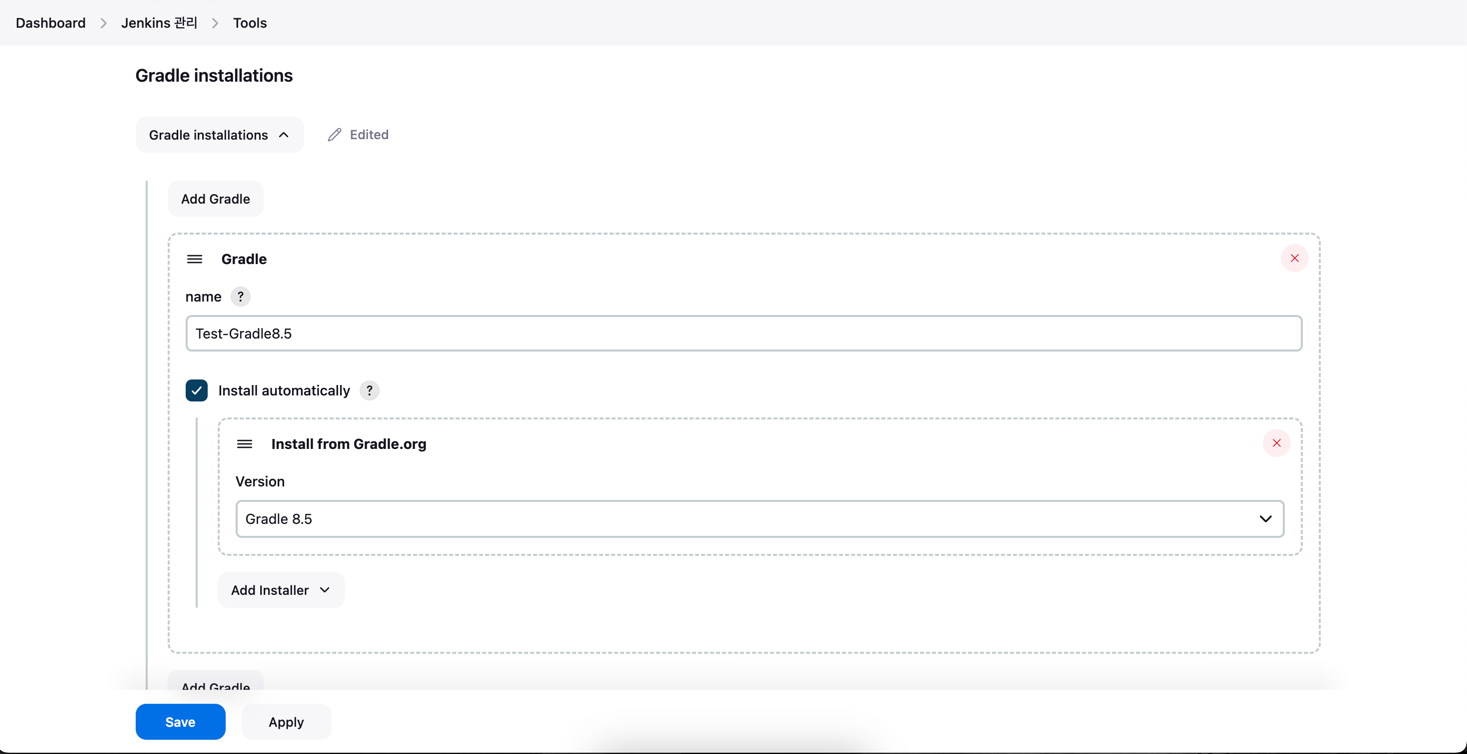
1. Docker 설치 및 셋팅
brew install docker
brew link docker
docker version
맥북으로 실습을 진행했다. 패키지 관리자인 brew를 통해 docker를 설치하는 것 부터 시작한다.
실습에서 기본적으로 MySQL을 사용한다. MySQL의 Image를 가져온다. 이때 버전을 기록하지 않으면 자동으로 Latest 버전을 가져오게 된다.
docker run -d -p 3306:3306 -e MYSQL_ROOT_PASSWORD=1234 --name mysql mysql
docker ps
docker exec -it mysql
MySQL 컨테이너를 생성해 주고 실행시켜 준다.
2. MySQL 연동과 데이터베이스 셋팅
위에서 실행한 컨테이너에서 MySQL에 접속해 준다. 암호는 위에서 설정한 1234를 참고한다.
CREATE DATABASE coupon_example;
USE coupon_example;
coupon_example 데이터베이스를 생성하고 메인 데이터베이스로 설정해 준다.
spring:
jpa:
hibernate:
ddl-auto: create
show-sql: true
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/coupon_example
username: root
password: 1234
Spring 프로젝트에 application.yml 파일에 위와 같이 접속 정보를 설정해 주면 기초 공사는 끝나게 된다.
요구사항
선착순 100명에게 할인 쿠폰을 제공하는 이벤트 진행
- 선착순 100명만 지급.
- 101개 지급은 안 됨.
- 순간적으로 몰리는 트래픽을 버텨야 한다.
초기 로직 구현 및 테스트
1. 쿠폰 생성 로직
public void apply(Long userId) {
long count = couponRepository.count();
if (count > 100) {
return;
}
couponRepository.save(new Coupon(userId));
}
쿠폰의 개수를 확인하고 개수가 100개를 넘었을 때 그냥 리턴해 준다. 100개가 넘지 않았을 경우 쿠폰을 생성해서 저장하는 간단한 로직으로 테스트를 진행한다.
2. 테스트 코드 작성
@Test
public void 한번만응모() {
applyService.apply(1L);
long count = couponRepository.count();
assertThat(count).isEqualTo(1);
}
간단하게 진행하면 정상적으로 응모가 되는 것을 확인할 수 있다.
초기 로직의 문제 발굴
초기 로직이 테스트 코드를 성공하면서 정상적으로 실행이 되었다고 오해할 수도 있다. 하지만 쿠폰 발급 이벤트는 동시에 여러번 실행이 될 것이다. 이런 상황을 가정해서 실행하면 문제가 나타난다.
1. 테스트 코드
@Test
public void 여러명응모() throws InterruptedException {
int threadCount = 1000;
ExecutorService executorService = Executors.newFixedThreadPool(32);
CountDownLatch latch = new CountDownLatch(threadCount);
for (int i = 0; i < threadCount; i++) {
long userId = i;
executorService.submit(() -> {
try {
applyService.apply(userId);
} finally {
latch.countDown();
};
});
}
latch.await();
long count = couponRepository.count();
assertThat(count).isEqualTo(100);
}
여러 개의 스레드로 쿠폰을 발급해 보는 테스트 코드이다. 해당 코드를 실행해 보면
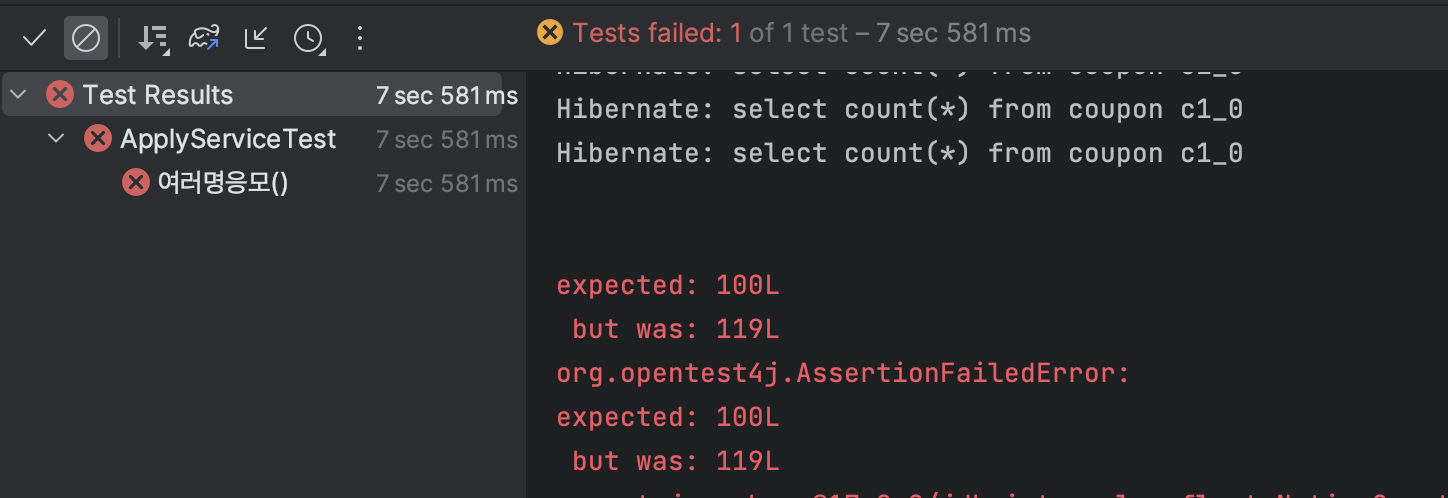 문제가 발생한 것을 확인할 수 있다.
문제가 발생한 것을 확인할 수 있다.
2. 문제는 레이스 컨디션(Race condition)
레이스 컨디션은 두 개 이상의 스레드가 공유 자원에 엑세스하고 활용하려고 할 때 생기는 문제로 위에서는 99개의 쿠폰이 있을 때 동시에 여러 스레드가 99개임을 인지하고 쿠폰을 발급해서 생기는 문제이다.
이런 상황을 이전에 회사에서 결제와 재고 처리로직 작성하면서 겪은 적이 있었는데 뮤텍스를 사용해서 처리했었다.
하지만 뮤텍스나 세마��포어를 사용한 방법 말고도 여러 방법이 있는데 Redis를 사용해서 먼저 해결해 본다.
Redis로 레이스 컨디션 해결하기
1. Redis setting
docker pull redis
docker run --name myredis -d -p 6379:6379 redis
위에서 MySQL을 셋팅했을 때와 마찬가지로 Redis Image를 Latest로 가져오고 컨테이너를 생성하고 실행�해 준다.
implementation 'org.springframework.boot:spring-boot-starter-data-redis'
Spring에서 의존성도 추가해 준다.
application.yml은 Redis를 생성할 때 따로 사용자 설정을 하지 않았기 때문에 위 의존성을 추가하면 알아서 디폴트로 연결해 준다.
따라서 따로 설정하지 않아도 Spring에서 local에서 실행하는 Redis에 접속할 수 있다.
2. Redis로 해결하려는 이유
Lock을 사용하면 생성하는 로직부터 발급하는 로직까지 Lock을 걸어야 한다. 때문에 성능에 불이익이 있다. 또한 synchronized를 사용하게 되면 마찬가지로 성능 저하가 생길 수 있고 서버가 늘어났을 때 소용 없게 된다.
선착순 이벤트는 쿠폰 개수에 대한 정합성이 중요하다. Redis를 사용하는 이유는 Redis에서 지원하는 incr이라는 예약어가 있는데 이는 Key에 대한 Value를 1씩 증가키신다.
기본적으로 Redis는 Single-Thread 기반으로 동작하기 때문에 문제도 없고 incr 자체의 성능도 좋아 정합성을 지키는데 문제가 없기 때문에 사용하기 적당하다 할 수 있다.
3. incr 테스트
docker exec -it 컨테이너ID redis-cli
Redis를 실행하고
incr coupon_count
incr coupon_count
incr 명령어를 실행하면 1씩 벨류가 증가하는 것을 확인할 수 있다.
4. Repository 코드
public long increment() {
return redisTemplate
.opsForValue()
.increment("couponCount");
}
Repository에 RedisTemplate을 사용해서 코드를 작성해주고 테스트 코드를 실행하면 통과하게 된다.
이는 Single-Thread인 Redis에서 숫자를 카운팅하기 때문에 각 스레드들이 가져가는 숫자가 겹치지 않게 되어 레이스 컨디션이 발생하지 않게 되는 것이다.
5. Redis를 사용한 레이스 컨디션 해결의 문제
Redis 자체에 문제가 있기 보다는 Redis를 통해 발급 수량을 체크하고 결국 저장은 RDB에 된다. 때문에 쿠폰이 많을수록 RDB에 부하를 주게 된다. 이때, RDB가 쿠폰 전용이 아니라 공통적으로 사용하는 경우 더 큰 문제가 생길 수 있다.
그럼 어떻게 하나? Kafka를 사용해서 이 문제를 해결할 수 있다.
Kafka를 사용해서 Redis의 문제를 해결하자
1. Kafka가 무엇인가?
Kafka는 분산 이벤트 스트리밍 플랫폼으로 이벤트 스트리밍은 소스에서 목적지까지 이벤트를 실시간으로 스트리밍하는 것을 말한다.
Kafka는 Pub/Sub 모델 기반의 메시지 큐인데 이 Pub/Sub은 메시지를 생성하는 서비스를 해당 메시지를 처리하는 서비스에서 분리하는 확장 가능한 비동기 메시징 서비스이다.
간단하게 설명하면 게시자 및 구독자라는 의미를 통해 게시자가 이벤트를 생성하면 같은 곳을 바라보고 있는 구독자는 해당 이벤트가 생성 됨을 알 수 있게 되는 것이다.
여기에서는 게시자 및 구독자를 Producer와 Consumer로 표현하고 발생하는 이벤트를 바라보는 통로를 Topic이라고 보겠다. 따라서 Producer -> Topic <- Consumer로 구성되어 동작한다고 보면 된다. 이때 Topic은 Queue 같은 통로로 보면 되고 데이터 삽입은 Producer에 의해서, 데이터 소비는 Consumer에 의해서 진행된다.
그럼 이제 간단하게 Kafka를 셋팅하고 테스트 해 보자.
2. Kafka 셋팅
version: '2'
services:
zookeeper:
image: wurstmeister/zookeeper
container_name: zookeeper
ports:
- "2181:2181"
kafka:
image: wurstmeister/kafka:2.12-2.5.0
container_name: kafka
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 127.0.0.1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
volumes:
- /var/run/docker.sock:/var/run/docker.sock
Spring에 docker-compose.yml을 생성해서 위와 같이 작성해 준다.
docker-compose up -d
docker-compose down
명령어를 통해 작성한 docker-compose 파일을 실행하고 종료한다. 실행 후에는 docker ps 명령어를 통해 실행이 정상적으로 되었는지 확인한다.
3. Kafka 테스트
docker exec -it kafka kafka-topics.sh --bootstrap-server localhost:9092 --create --topic testTopic
testTopic이라는 Topic을 생성한다. 말 그대로 테스트용이다. 생성이 완료되면 Created topic testTopic.라는 문구가 뜨게 된다.
docker exec -it kafka kafka-console-producer.sh --topic testTopic --broker-list 0.0.0.0:9092
이제 Topic을 삽입할 Producer를 실행해 준다.
docker exec -it kafka kafka-console-consumer.sh --topic testTopic --bootstrap-server 0.0.0.0:9092
마지막으로 Consumer를 생성해 줘야 하는데 Producer를 실행한 터미널을 놔두고 새로운 터미널을 열어주어 해당 명령어를 실행한다.
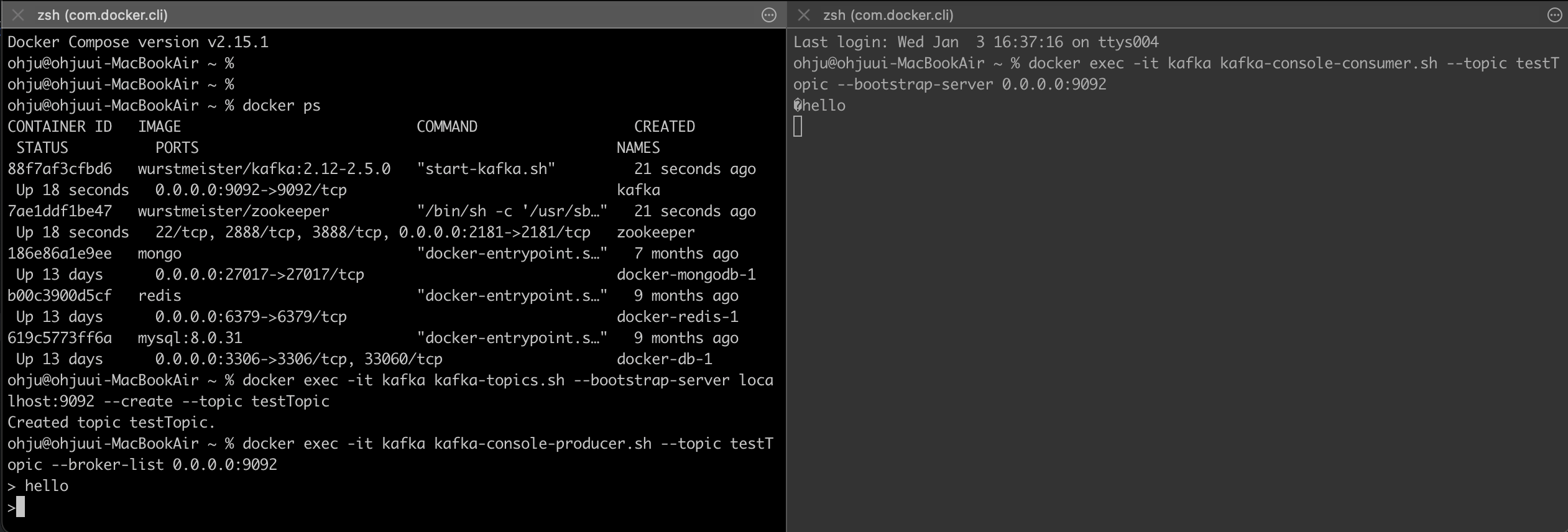 이후 Producer에서
이후 Producer에서 hello를 입력하면 같은 Topic을 바라보던 Consumer가 데이터를 가져와 출력하게 된다. 이제 테스트는 끝났다 Kafka 구현에 들어간다.
Kafka Producer 구현하기
1. 의존성 추가 및 config 작성
implementation 'org.springframework.kafka:spring-kafka'
Spring에 Kafka 의존성을 추가해 준다.
@Configuration
public class KafkaProducerConfig {
@Bean
public ProducerFactory<String, Long> producerFactory() {
Map<String, Object> config = new HashMap<>();
config.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
config.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
config.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, LongSerializer.class);
return new DefaultKafkaProducerFactory<>(config);
}
@Bean
public KafkaTemplate<String, Long> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
KafkaProducerConfig.java를 작성해 주고
@Component
public class CouponCreateProducer {
private final KafkaTemplate<String, Long> kafkaTemplate;
public CouponCreateProducer(KafkaTemplate<String, Long> kafkaTemplate) {
this.kafkaTemplate = kafkaTemplate;
}
public void create(Long userId) {
kafkaTemplate.send("coupon_create", userId);
}
}
Producer가 보낼 Topic을 지정해 준다. coupon_create로 설정해 주었다.
public void apply(Long userId) {
// long count = couponRepository.count();
long count = couponCountRepository.increment();
if (count > 100) {
return;
}
// couponRepository.save(new Coupon(userId));
couponCreateProducer.create(userId);
}
Service 로직에서 RDB에 저장하지 않고 Producer를 거치도록 변경해준다. (추후에 변경할 예정이니 일단을 이렇게 한다.)
2. Topic 및 Consumer 생성
docker exec -it kafka kafka-topics.sh --bootstrap-server localhost:9092 --create --topic coupon_create
터미널을 열어 coupon_create라는 Topic을 생성해 주고
docker exec -it kafka kafka-console-consumer.sh --topic coupon_create --bootstrap-server localhost:9092 --key-deserializer "org.apache.kafka.common.serialization.StringDeserializer" --value-deserializer "org.apache.kafka.common.serialization.LongDeserializer"
Consumer도 생성해 준다.
3. 테스트 실행
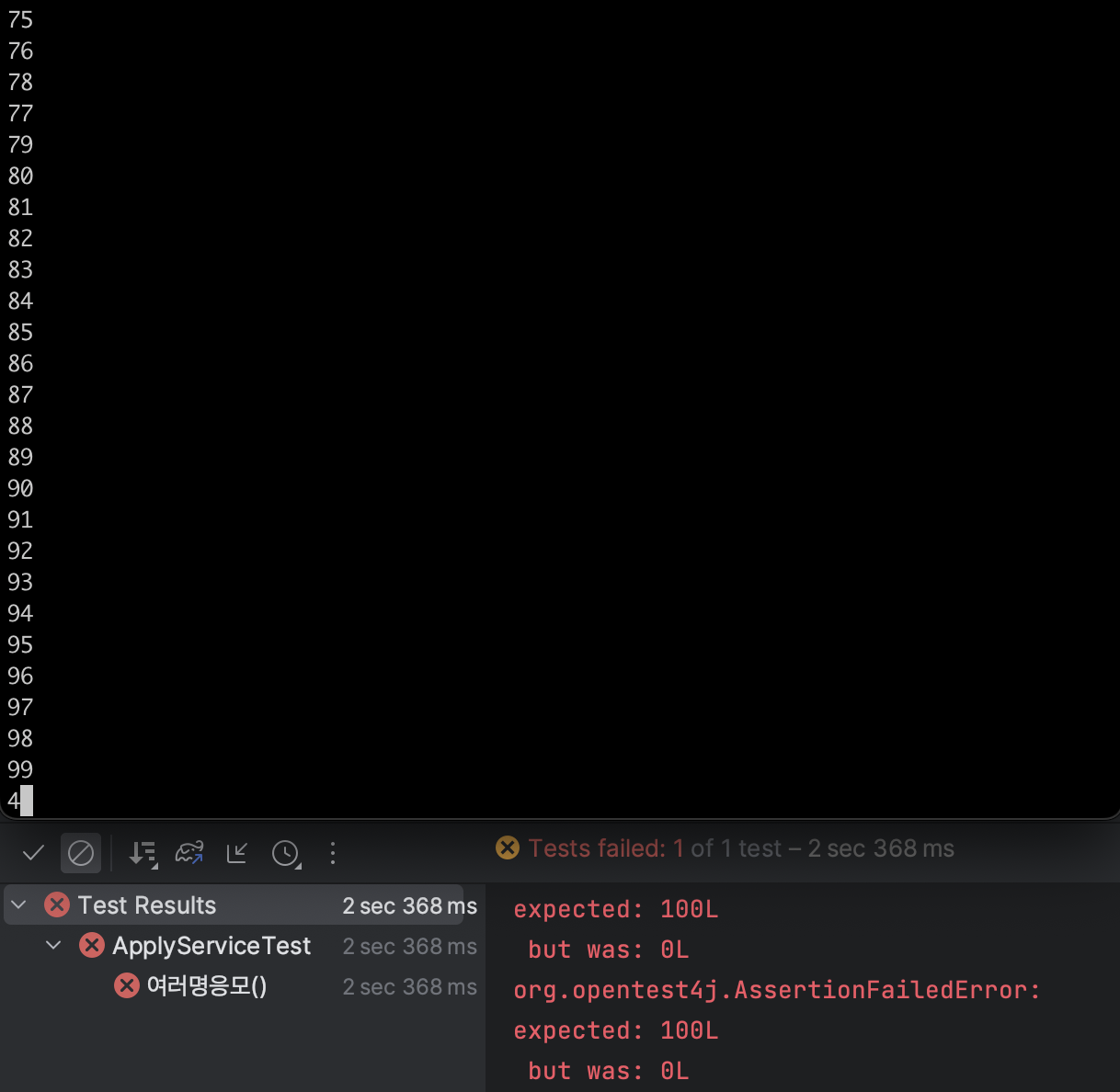 테스트 코드는 실패했다. 왜냐하면 위에서 RDB에 저장되는 부분을 지우고 Producer를 거쳐 게시하고 있는 Topic에 데이터를 보내주었기 때문이다.
테스트 코드는 실패했다. 왜냐하면 위에서 RDB에 저장되는 부분을 지우고 Producer를 거쳐 게시하고 있는 Topic에 데이터를 보내주었기 때문이다.
위에 터미널을 보면 무수한 값들이 표현되고 있다. 이는 Consumer를 실행한 터미널 창으로 Producer가 발생시킨 이벤트를 잘 받고 있는 것을 확인할 수 있다.
이렇게 Producer의 역할은 끝났다. 이제 Consumer를 구현해보자.
Kafka Consumer 구현하기
1. 새로운 프로젝트
이 프로젝트는 멀티모듈로 설계되었다. Consumer는 새로운 프로젝트로 구성한다. 새로운 프로젝트에 주입될 의존성은 아래와 같다.
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.springframework.kafka:spring-kafka'
runtimeOnly 'com.mysql:mysql-connector-j'
application.yml은 이전에 생성했던 것과 동일하게 넣어준다.
2. Consumer Config
@Configuration
public class KafkaConsumerConfig {
@Bean
public ConsumerFactory<String, Long> consumerFactory() {
Map<String, Object> config = new HashMap<>();
config.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
config.put(ConsumerConfig.GROUP_ID_CONFIG, "group_1");
config.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
config.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class);
return new DefaultKafkaConsumerFactory<>(config);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, Long> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, Long> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
}
마찬가지로 KafkaConsumerConfig.java를 작성한다.
@Component
public class CouponCreatedConsumer {
@KafkaListener(topics = "coupon_create", groupId = "group_1")
public void listener(Long userId) {
System.out.println("쿠폰이 생성되었습니다. userId : " + userId);
}
}
위에서 Producer(게시자)가 바라보는 토픽(coupon_create)을 구독하도록 설정해준다. 간단한 출력으로 그 결과를 확인해보자.
3. 테스트 실행
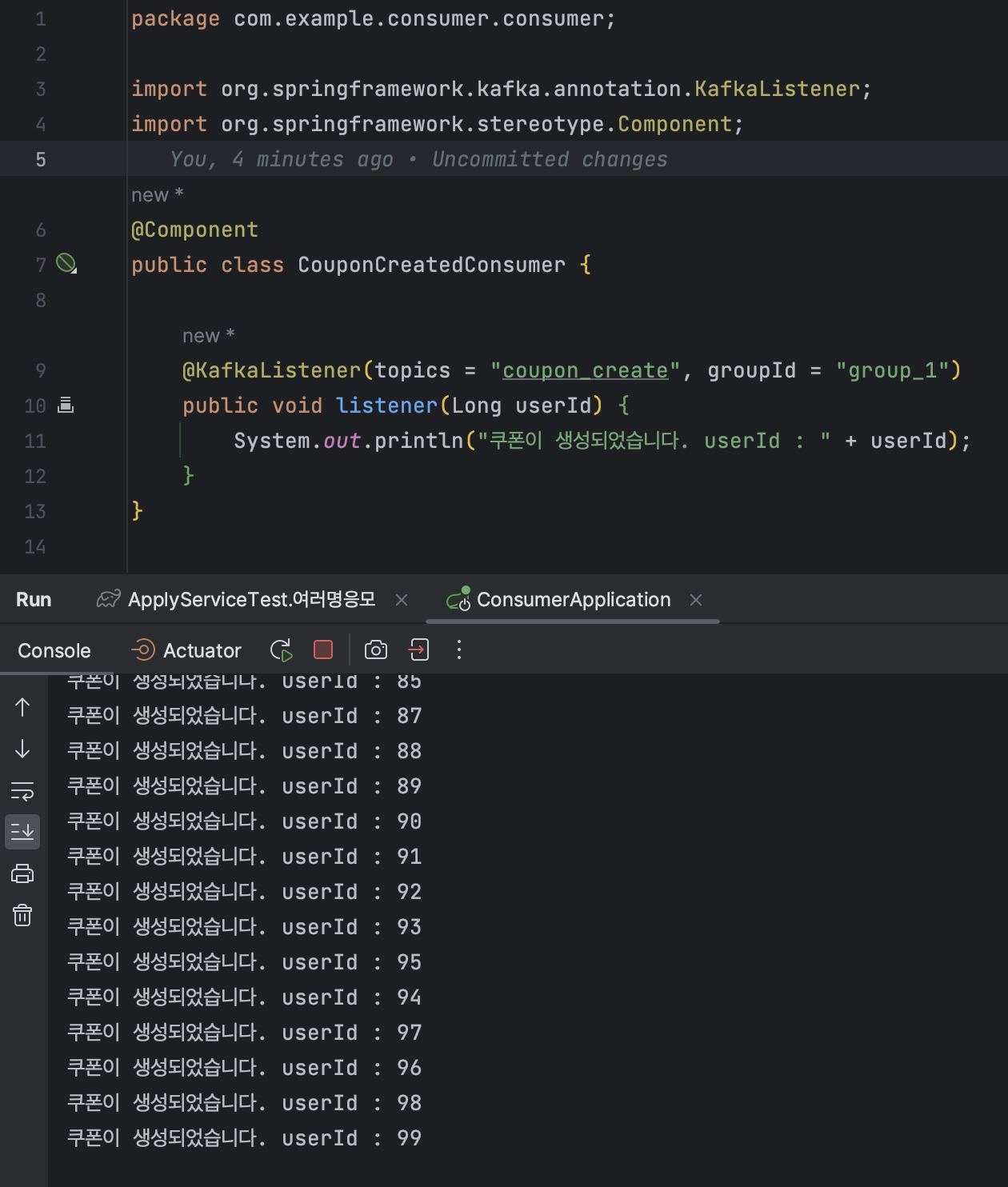 Producer가 Topic에 쏘는 데이터를 Consumer가 잘 받아오는 것을 확인할 수 있다.
Producer가 Topic에 쏘는 데이터를 Consumer가 잘 받아오는 것을 확인할 수 있다.
4. RDB에 저장시키기
@Component
public class CouponCreatedConsumer {
private final CouponRepository couponRepository;
public CouponCreatedConsumer(CouponRepository couponRepository) {
this.couponRepository = couponRepository;
}
@KafkaListener(topics = "coupon_create", groupId = "group_1")
public void listener(Long userId) {
couponRepository.save(new Coupon(userId));
}
}
이제 출력이 아니라 데이터베이스에 저장하도록 한다.
5. 다시 테스트
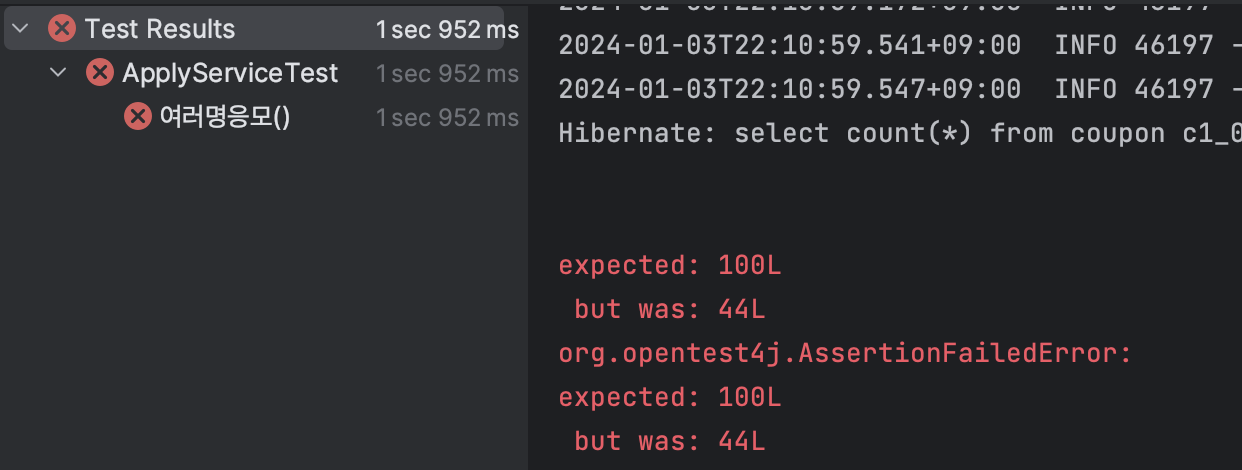 실패했다. 갑자기? 왜 실패했을까? 바로 데이터 처리 시간 차이에 따른 실패라고 볼 수 있다.
실패했다. 갑자기? 왜 실패했을까? 바로 데이터 처리 시간 차이에 따른 실패라고 볼 수 있다.
예를 들어 Producer가 데이터를 전송하고 완료하고 나서 테스트 케이스는 종료된다. 하지만 데이터는 Consumer가 받아서 처리한다. 그렇다. 테스트 케이스는 Consumer가 데이터를 처리하는 시간까지 기다리지 않았기 때문에 생긴 문제이다.
...
latch.await();
Thread.sleep(10000);
...
테스트 코드에 Thread sleep을 주어 충분히 Consumer가 처리할 수 있도록 기다려줘보자.
 성공했다.
성공했다.
요구사항을 추가해보자.
1. 추가되는 요구사항과 해결 방법
쿠폰 발급을 1인당 1개로 제한한다.
위와 같은 요구사항을 추가한다고 가정하자. 이를 해결하는 방법 또한 여러가지가 있다. 데이터베이스에서 유니크를 활용하는 방법도 있고 범위 락을 사용하는 방법도 있다. 예를 들면 아래와 같다.
// lock start
// 쿠폰 발급 여부
// if 발급 되었다면 return
// lock end
하지만 이런 범위 락은 성능 저하 이슈가 발생할 수 있기 때문에 다른 방법을 떠올려야한다. 마침, Redis에서 set을 지원한다. 이를 통해 해결해보자.
3. Redis Set
Redis는 sadd 키워드를 통해 Key, Value를 지정할 수 있다.
4. 로직 작성
@Repository
public class AppliedUserRepository {
private final RedisTemplate<String, String> redisTemplate;
public AppliedUserRepository(RedisTemplate<String, String> redisTemplate) {
this.redisTemplate = redisTemplate;
}
public Long add(Long userId) {
return redisTemplate
.opsForSet()
.add("applied_user", userId.toString());
}
}
Redis set을 사용하는 repository를 생성해 준다. opsForSet()을 사용하면 된다.
public void apply(Long userId) {
Long apply = appliedUserRepository.add(userId);
if (apply != 1) {
return;
}
// long count = couponRepository.count();
long count = couponCountRepository.increment();
if (count > 100) {
return;
}
// couponRepository.save(new Coupon(userId));
couponCreateProducer.create(userId);
}
Redis set에 userId를 저장하고 이미 쿠폰이 발급되어 있다면 그대로 return을 해 주어 1인 1개 쿠폰 발급을 진행한다.
5. 테스트 코드 작성 및 실행
@Test
public void 한명당_한개의쿠폰만_발급() throws InterruptedException {
int threadCount = 1000;
ExecutorService executorService = Executors.*newFixedThreadPool*(32);
CountDownLatch latch = new CountDownLatch(threadCount);
for (int i = 0; i < threadCount; i++) {
long userId = i;
executorService.submit(() -> {
try {
applyService.apply(1L);
} finally {
latch.countDown();
};
});
}
latch.await();
Thread.*sleep*(10000);
long count = couponRepository.count();
*assertThat*(count).isEqualTo(1);
}
생성되는 userId를 1로 고정했다. 새로 작성한 테스트 코드를 실행해서 확인하자.
 Consumer 터미널에 데이터가 1이 출력되고 테스트 케이스 역시 통과된다. 참고로 이전에 실행 내역이 있기 때문에 Redis에 저장된 데이터를 날려주는 것을 ��잊지 말아야 한다.
Consumer 터미널에 데이터가 1이 출력되고 테스트 케이스 역시 통과된다. 참고로 이전에 실행 내역이 있기 때문에 Redis에 저장된 데이터를 날려주는 것을 ��잊지 말아야 한다.
발급 실패한 쿠폰은 어떻게 처리하지?
그럼 발급에 실패한 쿠폰은 어떻게 처리할까? 따로 데이터베이스에 몰아서 저장시키고 배치 등을 사용해 다시 지급하는 방향으로 수정할 수 있다.
1. 발급 실패한 쿠폰 저장하기
@Entity
public class FailedEvent {
@Id @GeneratedValue(strategy = GenerationType.*IDENTITY*)
private Long id;
private Long userId;
public FailedEvent() {
}
public FailedEvent(Long userId) {
this.userId = userId;
}
}
FailedEvent 테이블을 생성해서 발급 실패한 쿠폰을 정의하고
@KafkaListener(topics = "coupon_create", groupId = "group_1")
public void listener(Long userId) {
try {
couponRepository.save(new Coupon(userId));
} catch (Exception e) {
logger.error("failed to create coupon :: " + userId);
failedEventRepository.save(new FailedEvent(userId));
}
}
쿠폰 생성할 때 실패한 경우 실패 테이블에 데이터를 쌓아준다. 역시 이후에 배치 등을 돌려 해당 쿠폰들을 처리해주면 된다.